This is a guest post by Andrey Adamovich
The first time, I gave a talk titled “Enterprise flight into DevOps space”, was in late 2014 at DevConFu conference. After that, I have delivered the presentation several times during 2015 at various conferences in Europe. For some time, I considered that a “closed topic” and did not really want to expand on it, until I was asked to deliver it again in 2016, and then again in 2017.
Enterprise is a word that is highly abused. Most people associate it with slow inefficient processes. Nobody wants to be there! At the same time, when I ask the audience: “How many of you work in the enterprise?” — over 95% raise their hands. Somehow, human nature makes us prefer simple models of the world. Even though, we, of course, totally understand – the world is way more complicated. Still, we are easily trapped into selecting good vs evil, being a start-up vs being an enterprise, developing microservices vs struggling with a monolith. Are most of us really on the evil/wrong side? Probably, not.
I’ve heard a lot of definitions of DevOps and most likely will hear even more in upcoming years, but what I’ve heard many times is that DevOps is solely related to start-up environments. I disagree with that statement. I strongly believe that successful start-ups will come to the DevOps culture (kind of) automatically because it’s the only way for them survive and conquer new markets given all the resource/time constraints. So, it’s not that interesting to talk about DevOps inside start-ups, since they by definition have a different approach to business (until they grow big enough and become slow enterprises, of course).
DevOps addresses many issues of small and big companies involved in IT, which is pretty much everywhere. Introducing DevOps principles inside slowly moving enterprises will discover inefficiencies and help to optimize processes and teams. Talking about DevOps in the enterprise is much more important than reflecting on experiences achieved by some high-performing start-ups.
Let me tell you the story of Jack the SysAdmin.
The story
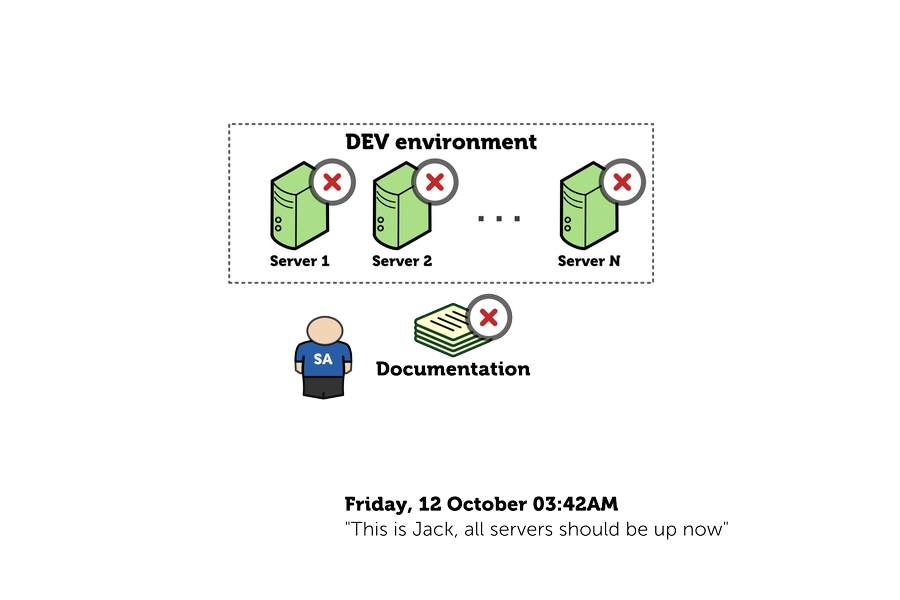
Once upon a time in the enterprise:
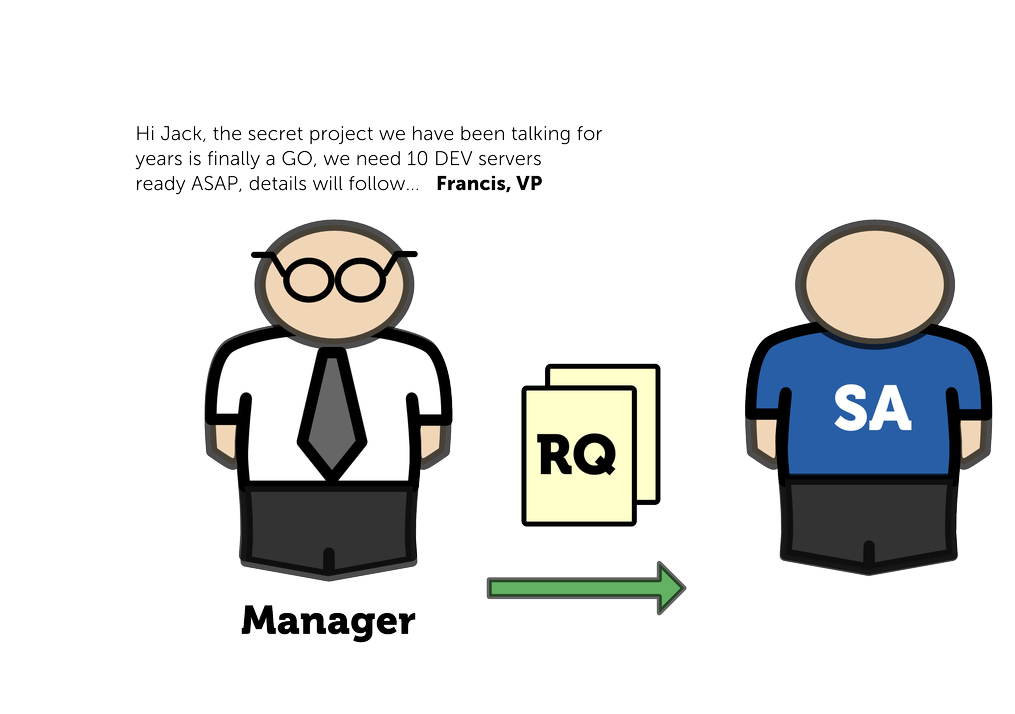
Jack knows what to do. Jack starts working.
After a couple of days:
After a few more of days:
After all, is done and documented, servers are handed over to the development team. Jack is happy. He did his job well. Requirements are fulfilled completely, documents and forms are filled according to Operations Department guidelines. All e-mails are sent, all animals are fed.
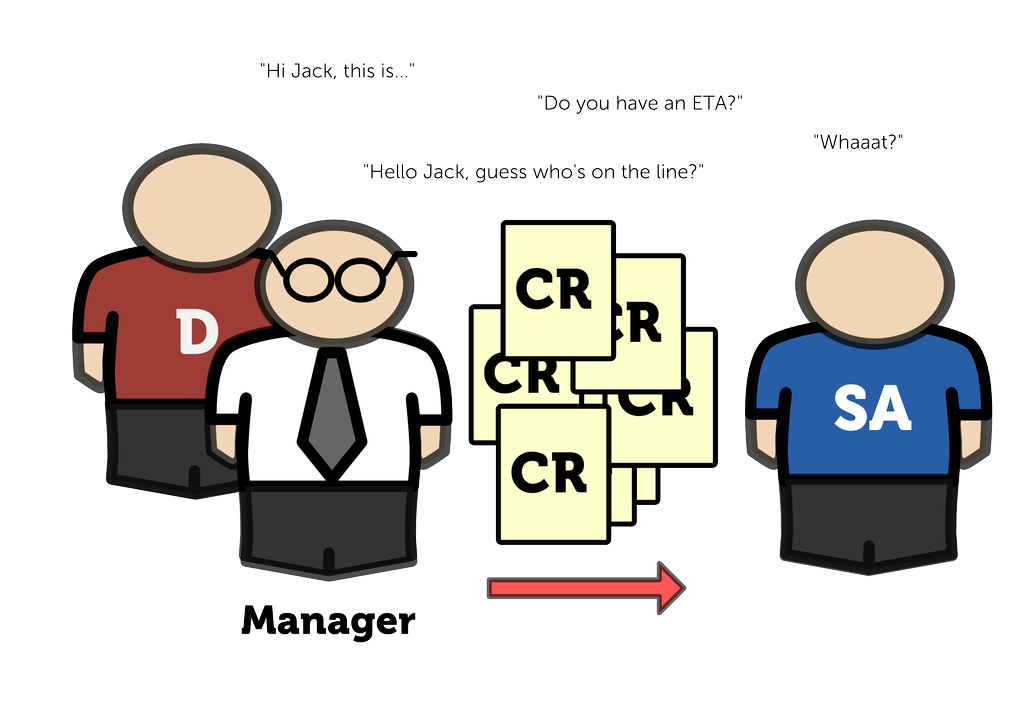
Developers have no idea who is Jack and were in the office he sits. The only way for them to change anything in the environment (in the “official” way) is to report to their manager, who will use organization’s issue tracking system to file a ticket to Operations Department, where Jack will pick it up. To speed up the process, project manager also sends an e-mail directly to Jack.

Jack has to obey and implement blurry change request in the way he understands that. Ka-boom! Developers can’t deploy. They start to complain. Jack has to fix the servers. It takes all night.
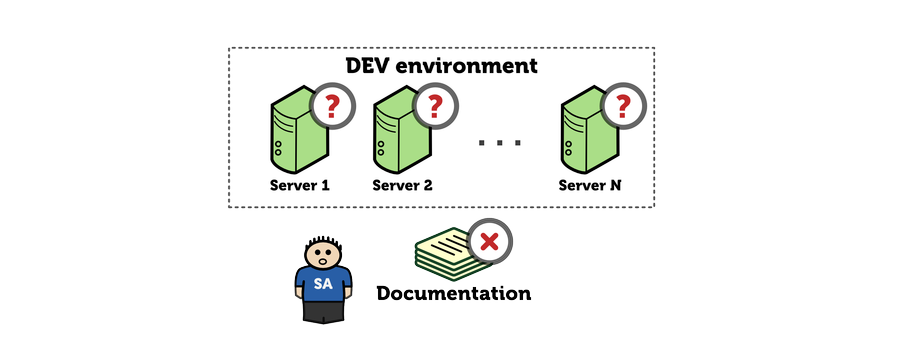
Things get worse with time. More change requests are entering the system. Also, developers, realizing that infrastructure change process is slow, start making some of the changes themselves to speed things up.
Infrastructure quickly flies into the state that is called THE UNKNOWN:
Somehow developers implement all the functionality and it kind of works in the development environment (and on my computer). It is time to move to the QA phase:
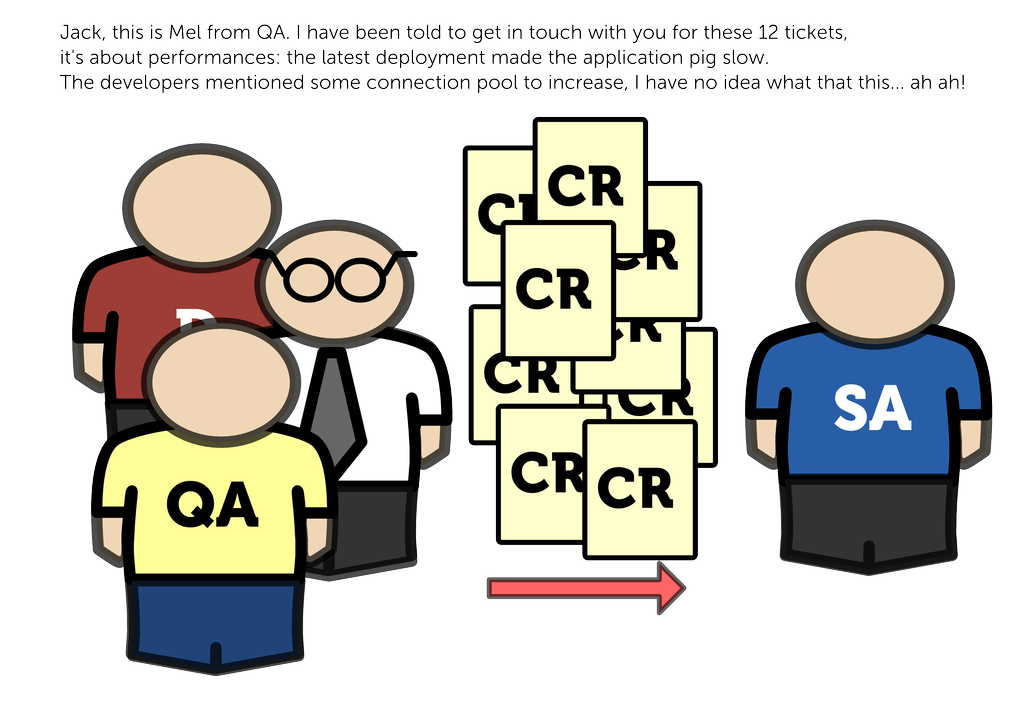
And we add more environments:
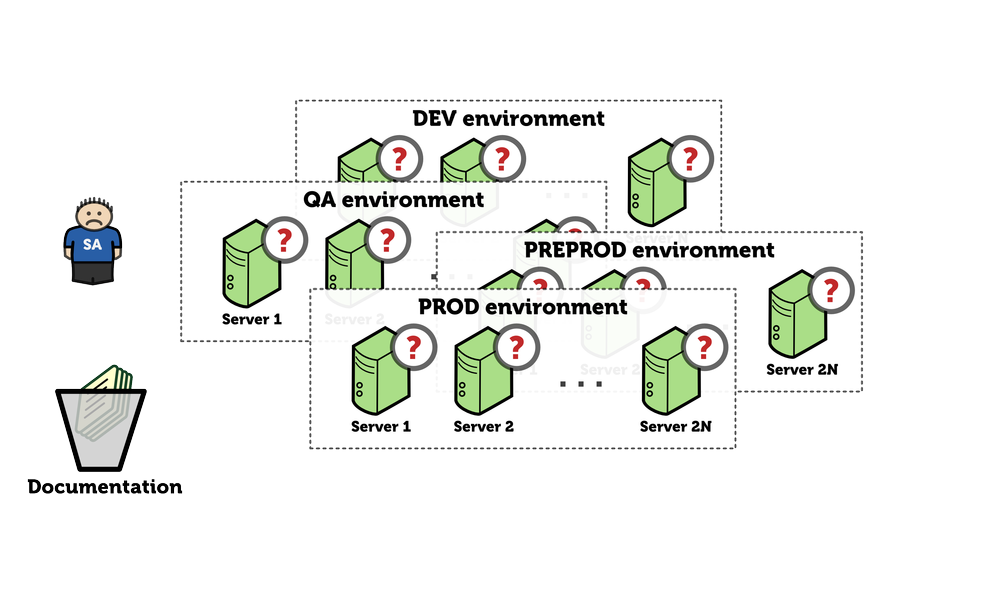
Things get complicated. Documentation does not serve the purpose anymore. Nobody knows how to configure the beast. Jack is overwhelmed with work. He does not cope. Solution? Let’s throw more people at that:
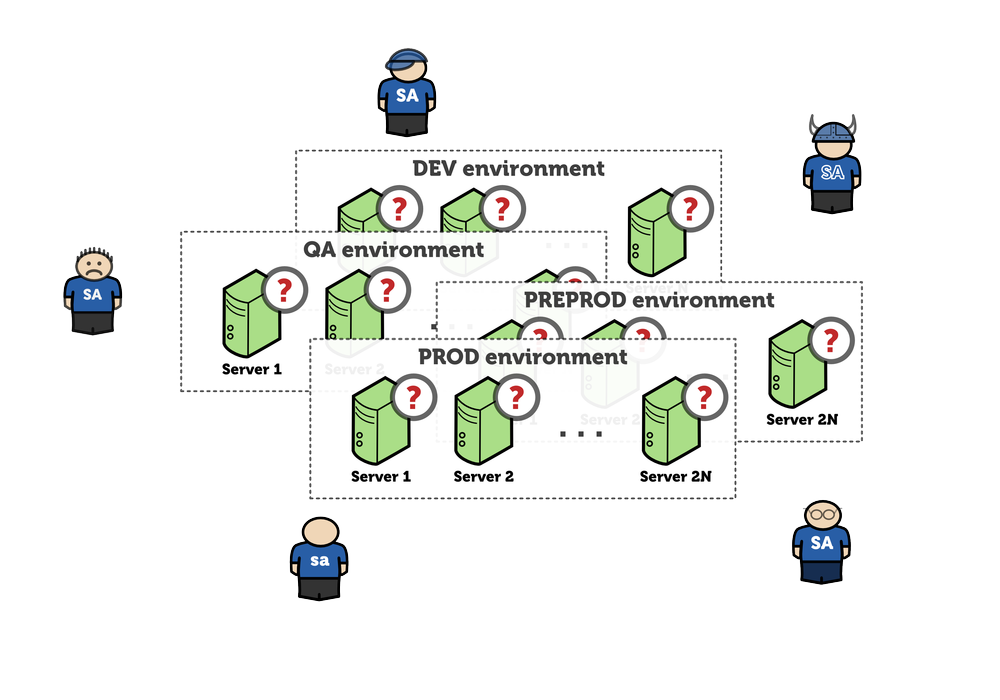
Again, somehow it is fixed. It’s not stable, but tolerable. The “go-live” date is approaching. Production becomes the most important environment:
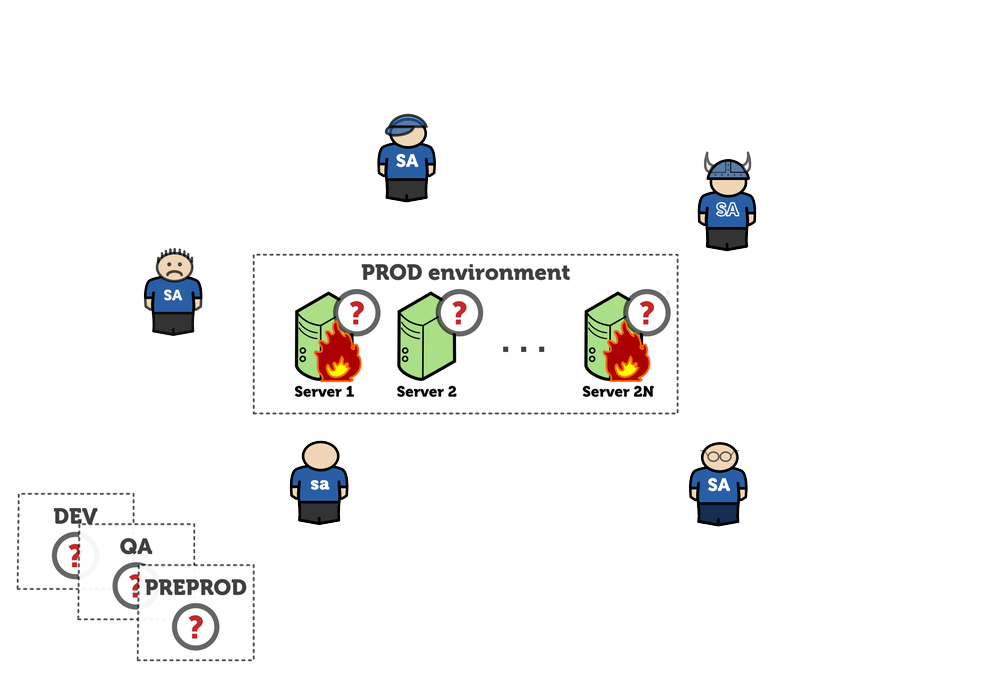
Production is catching fire every now and then. Monitoring does not help. Operations team monitors everything they usually do: CPU load, the amount of disk space, maybe network I/O, but they have no idea about vital application metrics like a number of incoming customer requests, how many of them are successful, how many active customers are in the system, etc. Therefore, the dashboards are green hiding the obvious problem with the application:
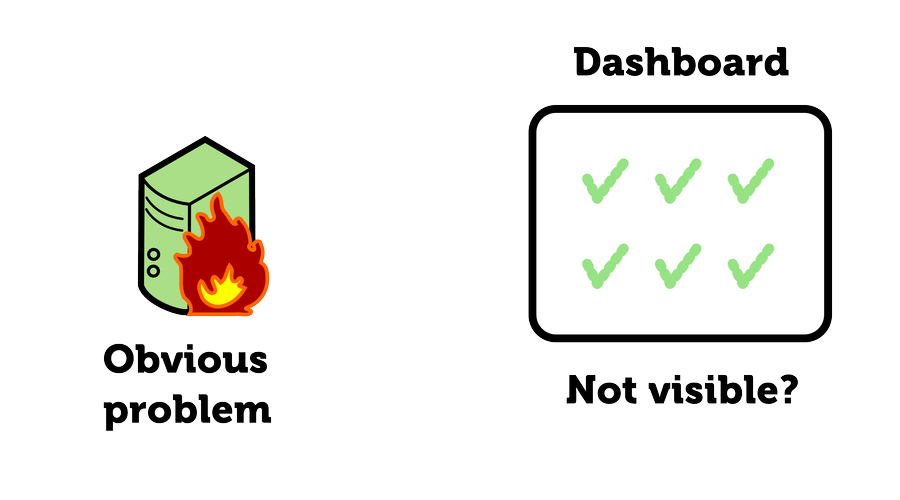
Project managers get a call from the customer much earlier than the team realizes there is a problem with the application. It takes few hours or days to find what is going on. Of course, after few incidents, the system is fixed and becomes better to some extent. Or maybe not. In any case, the trust of the customer is lost.
The end of the story. Well, at least of the first chapter.
When I ask my audience if this story is something they have already seen, I see quite many brave hands and many nodding heads. Some people even desperately scream: “Oh, yeah!”.
The problem
The problem is not in technology, the problem is the lack of communication, in the lack of cohesion between Devs and Ops and in treating Development and Operations roles as very much isolated phases of the same process.
That’s what often happens in many enterprises: communication is broken and only happens on the level of management meetings or issue tracking systems:
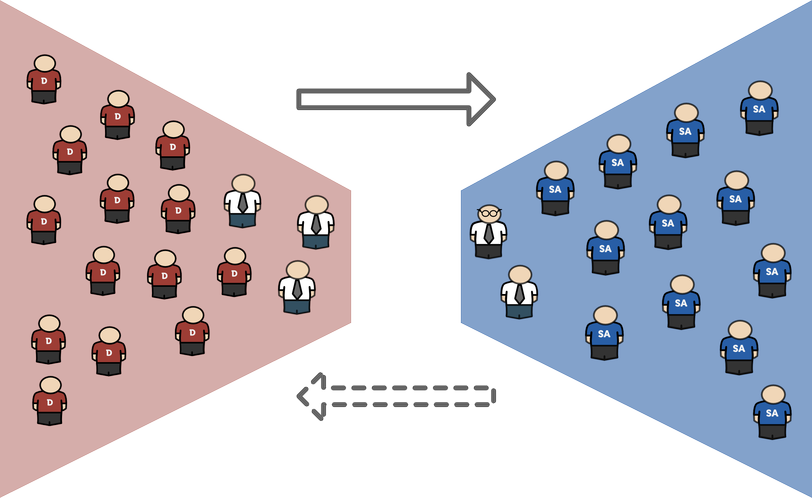
New or updated applications are just thrown as-is from development to production. The feedback cycle is slow and/or incomplete. Information, on how bad the application design is or how inconvenient it is to deploy, configure and monitor that application, is often not getting back to Developers or is considered not important. Developers continue to produce code that gives long working nights and weekends for Operators whose only task is to make it run.
On the other hand, Operations Department may prefer to hide behind the wall of “standard” platforms and force Developers to create new applications using outdated technologies. Willing to standardize may reach its extremes and produce quite rigid structures. That’s what it turns out to be in bigger companies where departmentalization is at its apogee:
Of course, when Development requirements and Operations capabilities are not aligned with each other or are aligned very late in the process, we get to the situation that nobody wants to be in. A number of unexpected issues grows.
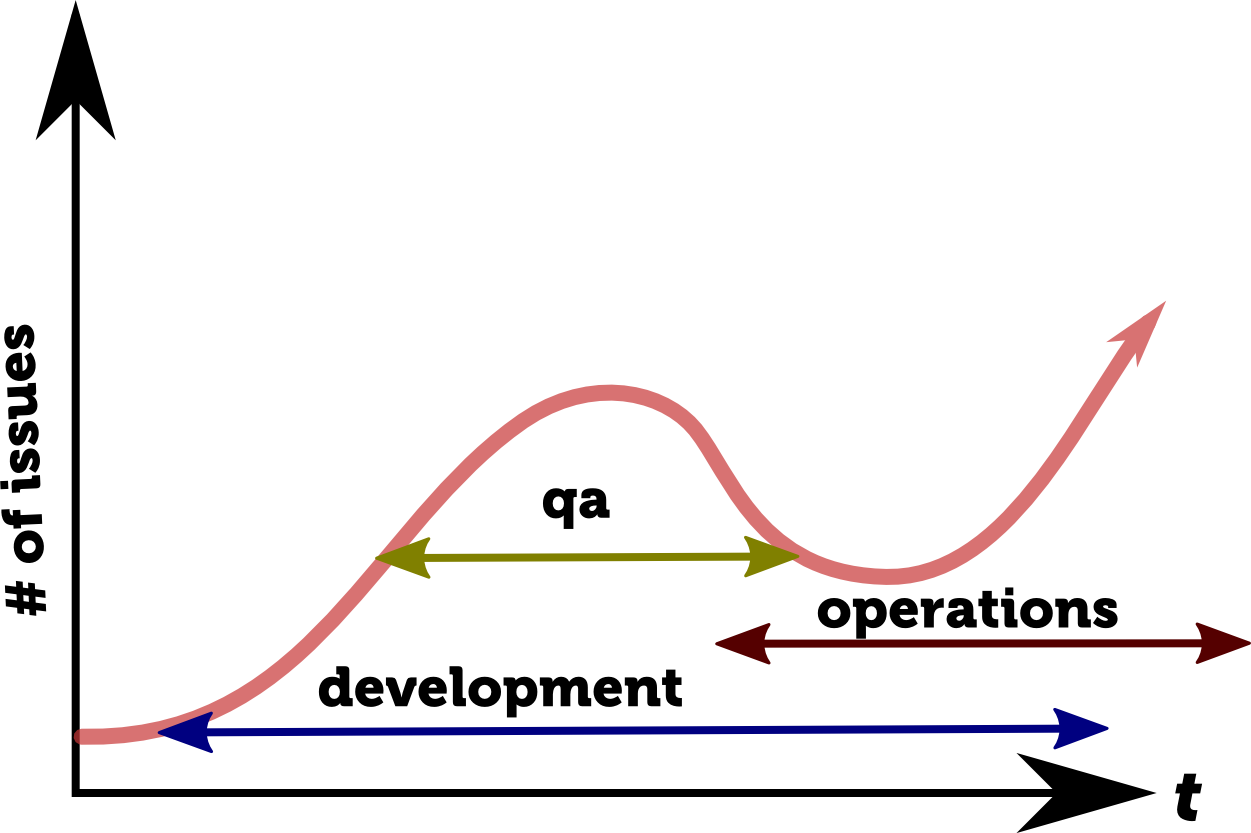
This is where enterprises need DevOps transformation, which is not about the tools and technologies (even though they definitely help), but about improved communication, reduced feedback cycle and higher empathy level.
The transformation
A communication model for DevOps should be transformed from 2 (or more) pyramids talking at the top of something that resembles the following state:
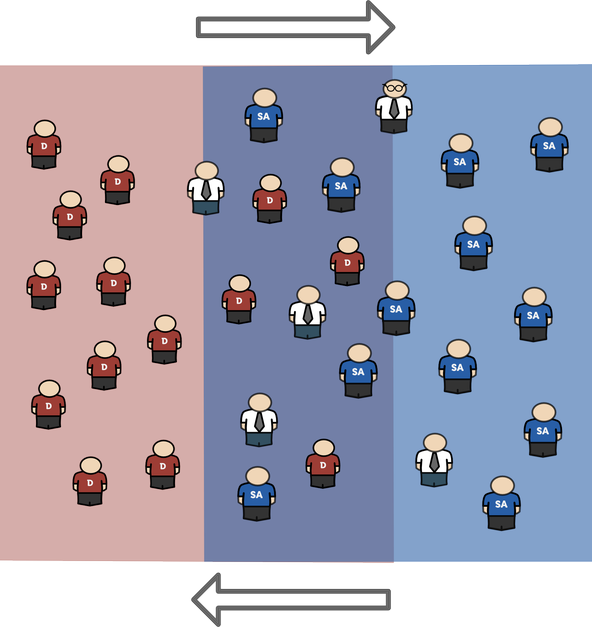
The picture above looks a bit like a football game. The two teams have conflicting targets, but they are playing by the rules, and the real goal is not to win each other (even though it will bring benefits to their department), but to bring joy to the spectators of the game i.e. the customers. Nobody wants to watch a game, where one team scores 20 goals and other one scores nothing; not many want to watch a game, where all players get red cards due to misbehaving. But the game, where equal competitors show their best skills and demonstrate fair-play and respect, will be remembered by the watchers and they would want to see it again.
The analogy with the football game probably can not be fully transferred to IT world, but at least some aspects of it seem interesting to me.
Enterprises – break the silos, invest into better communication, increase empathy! But do not replace DevOps transformation with tool selection. In 2017, tooling is not a problem anymore, but DevOps culture still is.
Interested to learn more about DevOps? Check Mozaic Works’s latest 1-day event on the topic.








